
How To Automate Your Server Database Backup Using Git
On this page
Backups are critical to ensure you never lose your database or media files, and thus, there are several options to choose from with various cost implications. One of my favorite guides on creating a bullet-proof backup plan is in this GitHub repository created by Jeff Geerling. At some point in the future, I’ll share my simplified backup strategy (don’t hold your breath).
But what if you need a cheap/free solution to back up database or system files from your servers? Are there any good solutions out there? Yes there are, and my bet is you already have all the software tools needed to set up a completely free remote backup automation. This article is a short guide to show you how to put these tools together.
Before we go into the details, I must mention that this method works flawlessly with containerized services i.e in Docker or Kubernetes, where the container’s system or database files are written to a mounted disk volume. However, if you don’t have containerized workloads on your server, this guide might work for you with a few tweaks.
Okay, let’s get in.
Setting Up A Git Repository
In my home-server setup, I have a number of containers running on a few machines. This allows me to ensure the machines themselves are stateless, and that any service can be moved with ease to a different machine. This also opens up a beautiful opportunity for automated backup, since the container volumes can be committed to a Git repository and version controlled just like a regular code base.
To set this up properly, you’ll need to have all container related files and volumes in a single root folder. This way, a git repository can be initialized in this root folder to keep track of all files you want added to the backup flow. I should also mention here that the Git method only works on text files i.e databases or other container files and not for object files like images or videos which are better backed up to services such as Amazon Glacier.
The Git route only works for text files
Go ahead to set up a remote GitHub repository to back up your container files. Ideally this repository should be private as anyone having access can replicate your entire server setup. The picture below shows my server repository, where containers are organized into folders containing their docker-compose.yml files as well as the database volumes and config files:
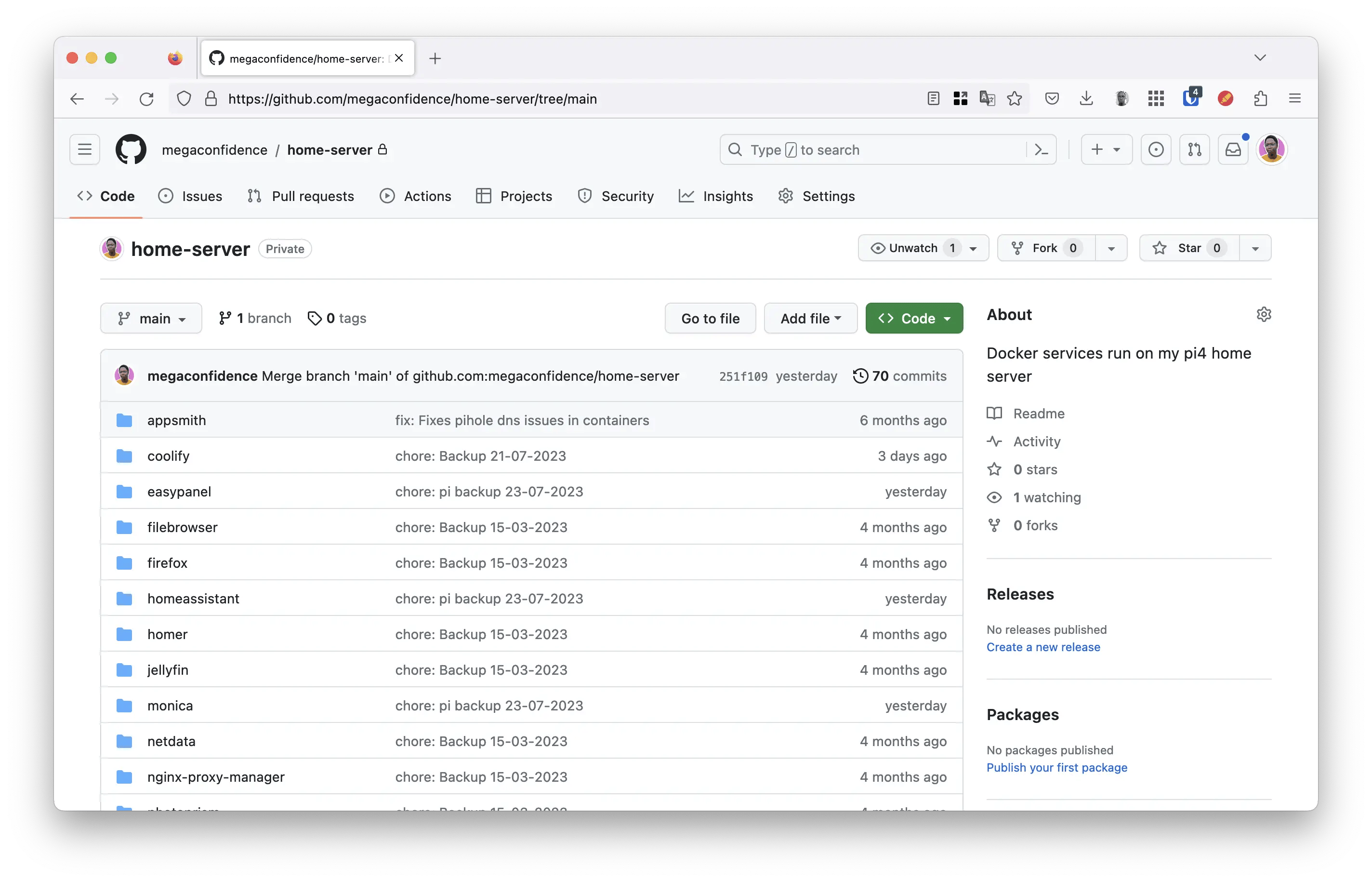
The most important piece of setting up your repository is your .gitignore file. This is where you specify what files or folder you want added to the repository, and you can think of it as the brains of the entire operation. Here’s an example of my .gitignore file:
# files to ignore
logs.*
*.log*
utils/.env
# folders to ignore
**/log
**/logs
photoprism/*
pihole/etc-pihole/*
transmission/config/
pihole/etc-dnsmasq.d/
nginx-proxy-manager/data/
plausible/event-log/*
# folders to strictly backup
!homer/
!monica/
!plausible/
!homeassistant/
!pihole/etc-pihole/custom.list
!syncthing/config/config.xmlSo in summary, if there’s a file or folder you want added to the backup automation, simply add a path to the folder with a leading negation operator i.e !path/to/folder/with/db/files. Conversely, folders or files you want ignored during backup should be added i.e path/to/unwanted/log/folder. All files or folders not ignored will be added to the backup repository.
Figuring out what folders to add may require some poking around the container volume to find out where the important files are stored. Thankfully, that shouldn’t take too long.
Creating A Backup Script
At this stage, our backup automation isn’t really an automation because it only works when files are manually committed and pushed to the remote Git repository. Let’s change that by creating a backup.sh shell script that does all the work. This script could be added to the repository based on your preference:
#!/bin/bash
# perform this shell script in the server repository folder
cd ~/your-reposotory-path-here/
# stop all runing containers
sudo service docker stop
# fix file perission issues
sudo chown -R $(whoami) ./
# perform git backup
git add .
git commit -m "chore: Backup $(date +'%d-%m-%Y')"
git pull
git push
# restart docker containers
sudo service docker startThe backup script is pretty straight forward. It’s starts off by navigating the shell to the root Git folder containing the server files, then it stops all running containers and fixes potential permission issues on the files created by the containers. Then, it creates a new commit of files changed since the last backup and pushes them to the remote Git repository. And finally, it restarts the containers after the backup is complete.
To ensure this script runs properly, you need to give it execution permissions by running sudo chmod +x ./backup.sh. Then you can give it a test run by executing the script i.e ./backup.sh.
Automating The Backup Flow
So far, we’ve set up a remote Git repository to store important server files and databases, and we’ve also put together a useful script container all required commands to perform the backup. The missing piece is to automatically invoke the backup script without manual intervention. Creating a cron job solves this problem.
To create a cron entry for the backup script, run crontab -e and you may be asked to select a text editor (Nano is a good choice). To create a cron job, add an entry containing a cron expression of the time and frequency you want the backup script executed, a shell program to execute the script i.e bash, a path to the backup script, and optionally, a path to the backup log file to keep track of executions. Your entry should look like this:
#| exp | shell | path-to-backup-script | path-to-log-file (optional)
0 0 * * * /bin/bash ~/your-reposotory-path/backup.sh >> ~/your-reposotory-path/backup.log 2>&1The cron expression 0 0 * * * will run your backup script every day at midnight. If you aren’t familiar with cron expressions, this tool may be of help.
Summary
Awesome! This was a quick guide on setting up a free remote database backup for your servers. If you’d love to learn about a free backup strategy for media files, follow me Twitter for more updates. Till then, see ya!